The Cases That Never Existed
The citations looked real. The judges looked real. The cases had never existed.

The Search for Precedent
In early 2023, a routine lawsuit against an airline found itself at the center of a controversy that would eventually be cited in countless discussions about artificial intelligence. At the time, however, nobody involved believed they were witnessing a technological failure. To the court, it appeared to be a straightforward legal dispute. To the attorneys involved, it was another filing among thousands submitted to American courts every year.
The trouble began when a legal brief submitted on behalf of the plaintiff cited several previous court decisions that were supposedly relevant to the case. On paper, there was nothing unusual about them. The citations followed the expected format, the case names sounded authentic, and the accompanying legal arguments appeared detailed enough to survive a casual review. If anything, the research looked thorough.
That confidence did not last long.
While reviewing the filing, opposing counsel attempted to locate the cited decisions and quickly encountered an unexpected problem. The cases could not be found. Legal databases returned nothing. Court records returned nothing. Searches that should have taken seconds instead produced dead ends. At first, this seemed like the sort of mistake that occasionally appears in legal work - a typographical error, an incorrect citation, or perhaps a misunderstanding regarding the name of a case.
The situation became considerably stranger when the attorneys who submitted the brief maintained that the cases were real. When questioned, they provided additional information and documentation supporting the citations. The cases appeared to have judges, procedural histories, legal reasoning, and quotations that neatly supported the argument being made. Everything looked legitimate.
Yet every attempt to verify their existence reached the same conclusion.
The cases had never existed.
What made the situation remarkable was not merely that the citations were incorrect. Lawyers make mistakes, and courts deal with those mistakes regularly. The unusual part was the level of detail involved. These were not incomplete references or partially remembered precedents. They were fully formed legal decisions that appeared convincing enough to make it through the drafting process and into a federal court filing.
As the court investigated further, the explanation that eventually emerged was stranger than anyone initially suspected. The attorney responsible for the research had not invented the cases himself, nor had he intentionally attempted to mislead the court. Instead, he had relied on a tool that millions of people were beginning to experiment with at the time: ChatGPT.
When asked to help identify relevant legal precedents, the model generated a collection of cases that looked entirely authentic. The names sounded plausible. The citations resembled genuine legal references. The quotations read like passages taken from actual judicial opinions. Unfortunately, none of them existed outside the conversation in which they were generated.
The incident would eventually become one of the most widely discussed examples of AI hallucination, a term that was rapidly entering the public vocabulary as large language models became more common. For many observers, the story served as a warning about trusting AI-generated information. Yet the real lesson was more interesting than a simple cautionary tale. The model had not failed in the way most people imagined. In a sense, it had done exactly what it was designed to do.
To understand why, we first need to understand what a hallucination actually is - and why systems that produce remarkably intelligent answers can sometimes fabricate information with extraordinary confidence.
Plausibility Over Truth
The immediate reaction to the Mata case was understandable. A system had generated court cases that never existed, a lawyer had trusted them, and the mistake had ultimately found its way into a federal court filing. To many observers, the lesson seemed obvious: artificial intelligence sometimes makes things up.
While true, that explanation barely scratches the surface of what actually happened.
The phrase AI hallucination is often used to describe situations where a model produces information that is factually incorrect, unsupported by evidence, or entirely fabricated. Put simply, a hallucination occurs when a model generates information that lacks factual grounding but presents it as though it were true.
The term itself can be somewhat misleading because it implies a malfunction, as though the model briefly lost touch with reality. In practice, hallucinations are not an unusual failure mode that occasionally appears in otherwise perfect systems. They are a natural consequence of how modern language models work.
Most people imagine AI systems as sophisticated search engines. They ask a question, the model searches through a giant internal database of facts, retrieves the relevant information, and presents an answer. If that were true, hallucinations would be relatively rare because factual questions would simply require factual retrieval.
Large language models do not work that way.
At their core, they are prediction engines. During training, they consume enormous amounts of text and learn statistical relationships between words, phrases, concepts, and patterns. When a user asks a question, the model is not searching for truth. Instead, it is estimating what sequence of words is most likely to follow the prompt it has been given.
This distinction may sound subtle, but it changes everything.
When ChatGPT generated fictional airline cases for the attorney in the Mata litigation, it was not intentionally deceiving anyone. The model had learned what legal citations typically look like. It understood the structure of case names, the language of judicial opinions, and the style of legal argumentation. Faced with a request for relevant precedents, it generated something that statistically resembled legitimate legal precedent. The result was professionally written, internally consistent, and completely detached from reality.
In other words, the model optimized for plausibility rather than truth.
This is precisely what makes hallucinations dangerous. An obviously absurd answer rarely causes harm. If an AI claims that the Roman Empire invented smartphones, most people immediately recognize the error. The dangerous hallucinations are the ones that remain close to reality: a legal citation that looks authentic, a medical recommendation that omits a critical detail, a statistic that is slightly wrong, or a software recommendation that introduces a subtle security vulnerability.
These errors often survive because they do not look like errors.
The severity of the problem also depends heavily on the domain. A hallucination during casual conversation is usually harmless. If an AI incorrectly states the release date of a movie, the consequences are minimal. In fields such as healthcare, law, finance, or cybersecurity, however, the same behavior can produce outcomes that are far more serious. A fabricated legal precedent can influence a court filing. An incorrect medical recommendation can affect treatment decisions. A hallucinated security practice can expose systems to attack.
This is why researchers often describe hallucination not as an occasional mistake but as one of the central challenges facing modern AI systems. The issue is not that models sometimes produce incorrect information. Humans do that as well. The issue is that language models can present uncertainty in exactly the same tone, structure, and confidence as verified facts.
For centuries, fluency has been one of the signals humans use to judge credibility. We tend to trust information when it is delivered clearly, confidently, and professionally. Hallucinations exploit that instinct because the output often appears indistinguishable from genuine expertise.
The result is a strange paradox. The same capabilities that make modern AI systems useful are also the source of one of their most significant weaknesses. The better a model becomes at sounding knowledgeable, the harder it becomes to recognize when it is merely guessing.
Confidence Without Evidence
If hallucinations are a natural consequence of how language models operate, the next question is obvious.
Why do they happen so confidently?
To understand why, it helps to imagine a model's training data as a map. Some regions of that map are densely populated with examples. Others contain only a handful of observations. A few regions may contain almost none at all.
When a model receives a question that falls within a dense region, it has abundant examples from which to learn. It has seen similar patterns repeatedly and can often produce reliable outputs. Problems begin when the model is asked to make predictions in areas where its experience is limited.
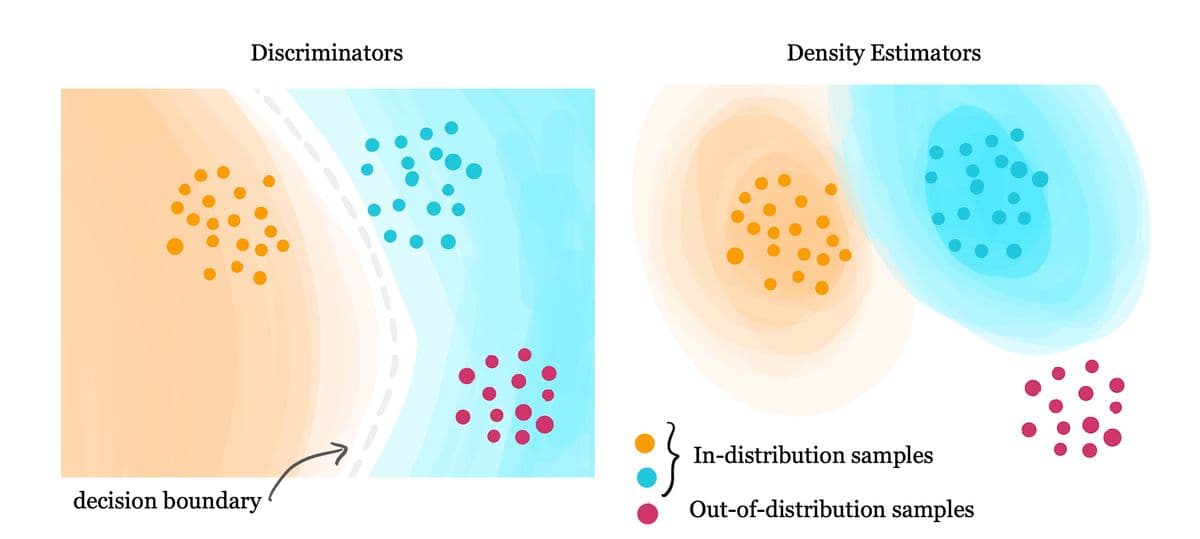
Figure 1: Models generally perform best on data that resembles what they encountered during training. As inputs move further away from those familiar regions, prediction quality and confidence can become increasingly disconnected. [Source: https://medium.com/geekculture/out-of-distribution-detection-in-medical-ai-b638b385c2a3]
This limitation exists across machine learning, not just language models.
Consider a simplified insurance system trained to predict whether a claim should be flagged as high risk. During training, the model might observe thousands of examples involving smokers, non-smokers, diabetic patients, and various BMI categories. Most of its data may indicate that smokers tend to generate higher healthcare costs.
Now imagine a very unusual combination of attributes appears during deployment. Perhaps the applicant belongs to a subgroup represented by only a handful of examples in the entire training dataset. The model possesses very little direct evidence about that specific population.
Suppose the model has seen thousands of smokers but only a single underweight smoker. If that lone example happened to generate unusually high healthcare costs, the model may learn a rule that dramatically overstates the risk of similar applicants in the future. Despite having almost no evidence, it may still assign a denial probability of 95 percent or higher simply because it is extrapolating from a pattern it barely understands.
The result is a prediction that appears highly certain despite being built on remarkably weak foundations.
This phenomenon is not unique to insurance systems. Recommendation engines encounter it when suggesting content to users who do not resemble anyone in their training data. Medical models encounter it when evaluating rare patient profiles. Fraud detection systems encounter it when analyzing transactions unlike anything they have seen before.
Large language models simply make this behavior more visible because they express their predictions through language.
When ChatGPT fabricated legal cases in the Mata litigation, it was doing something surprisingly similar. The model understood what legal citations looked like. It understood how legal arguments were structured. It understood the patterns surrounding airline litigation. What it lacked was evidence that the specific cases actually existed.
Rather than retrieving facts, it extended familiar patterns into unfamiliar territory.
The output looked authoritative because the model had mastered the language of authority.
In practical terms, a hallucination is often less like a lie and more like an overconfident guess. The model has identified a pattern, extended it beyond the boundaries of its knowledge, and presented the result without recognizing that it has entered unfamiliar territory.
The problem is not that the model knows too little.
The problem is that it rarely knows when it knows too little.
Knowing That You Don't Know
A natural response to hallucinations is to ask why models do not simply admit uncertainty.
At first glance, the solution seems obvious. If a model lacks sufficient evidence, it should simply say "I don't know" rather than risk generating an incorrect answer.
The difficulty is that uncertainty itself is surprisingly hard to measure.
A language model does not possess a separate internal mechanism that tracks what it knows and what it does not know. Instead, it generates responses by predicting probable continuations of text. The confidence associated with those predictions is not necessarily the same as confidence that the final answer is correct.
This distinction matters because a model can be extremely confident in the words it generates while being completely wrong about the claim those words are making.
Researchers refer to this problem as calibration.
A well-calibrated system should be correct roughly 80 percent of the time when it expresses 80 percent confidence. In practice, however, many language models struggle to maintain that relationship consistently. Their confidence often reflects the strength of patterns they have learned rather than the quality of evidence supporting the answer.
Recent research suggests that this remains a challenge even for advanced reasoning models. In late 2025, researchers introduced KalshiBench, a benchmark designed to evaluate whether language models can accurately assess their own uncertainty regarding future real-world events. The results revealed an interesting pattern. Some models achieved similar levels of accuracy, yet differed significantly in how well they estimated their own uncertainty. In other words, two models could arrive at roughly the same number of correct answers while having very different levels of confidence in those answers.
More surprisingly, additional reasoning did not always improve calibration. In some cases, models became more confident without becoming meaningfully more accurate.
This highlights an important misconception about AI systems. Better reasoning and better self-awareness are not necessarily the same thing.
A model may become more capable of solving complex problems while simultaneously becoming more confident in its mistakes.
The challenge extends beyond language models. Throughout machine learning, systems are typically rewarded for producing useful answers rather than accurately measuring uncertainty. During training, a correct guess is still rewarded as a success, even if the model had little evidence to justify it. Over time, this creates a tendency to extrapolate rather than acknowledge ignorance.
From a statistical perspective, that behavior is not entirely irrational. If a model occasionally reaches the correct answer through extrapolation, guessing can improve overall performance. Unfortunately, the same behavior also creates hallucinations when those guesses fail.
This leaves researchers with a difficult trade-off.
Suppose we aggressively discourage hallucinations by forcing a model to refuse uncertain questions. The system may become safer, but it may also become far less useful. Questions that previously received reasonable answers may now receive generic refusals. Useful reasoning paths may be abandoned simply because the model lacks complete certainty.
Researchers sometimes refer to this phenomenon as over-conservatism. In trying to prevent hallucinations, we risk creating systems that become reluctant to answer legitimate questions at all.
The result is that reducing hallucinations is not simply a matter of making models smarter. It is a balancing act between helpfulness, accuracy, confidence, and uncertainty. Improving one of those qualities often comes at the expense of another.
Teaching a system to generate information is difficult.
Teaching it to recognize the boundaries of its own knowledge may be even harder.
Trust, But Verify
If hallucinations are a natural consequence of how modern language models generate text, it might seem as though the problem has no solution.
The answer is both yes and no.
Researchers have largely stopped searching for a single technique that completely eliminates hallucinations. Instead, the focus has shifted toward building systems that reduce the likelihood of hallucinations, detect them when they occur, and limit the damage they can cause.
In practice, many of the most successful AI products today are not simply language models. They are collections of retrieval systems, verification layers, guardrails, and monitoring tools built around those models.
The most widely adopted approach is known as Retrieval-Augmented Generation, or RAG.
To understand why RAG exists, consider what happened in the Mata case. When ChatGPT was asked to provide legal precedents, it relied entirely on patterns learned during training. It had no mechanism forcing it to consult a verified legal database before generating an answer.
A retrieval-based system approaches the problem differently.
Before generating a response, the system first searches a trusted source of information. This may be a legal database, a company's internal documentation, a collection of medical records, or any other verified knowledge repository. Only after retrieving relevant material does the language model generate an answer.
 Figure 2: Retrieval-Augmented Generation (RAG) grounds model outputs in external sources by introducing a retrieval step before generation. [Source: https://developers.llamaindex.ai/python/framework/understanding/rag/]
Figure 2: Retrieval-Augmented Generation (RAG) grounds model outputs in external sources by introducing a retrieval step before generation. [Source: https://developers.llamaindex.ai/python/framework/understanding/rag/]
This seemingly simple change produces an important shift in behavior.
Instead of relying solely on what was absorbed during training, the model is now anchored to external evidence. The question changes from "What do you know?" to "What can you find, and what does the evidence say?"
This dramatically reduces many forms of hallucination, but it does not eliminate them.
A model can still misunderstand a document. It can still ignore important evidence. It can still combine information from multiple sources incorrectly. Retrieval narrows the space in which hallucinations occur, but it does not remove the underlying tendency to generate plausible text.
This realization has led to a second layer of defense: verification.
Many production AI systems no longer rely on a single model response. One component may generate an answer while another checks citations, verifies claims, or searches for inconsistencies. In some architectures, multiple models effectively critique one another before a final response is delivered to the user.
The idea is surprisingly familiar.
Journalists have editors. Researchers have peer reviewers. Courts have opposing counsel. Critical decisions are rarely trusted to a single source without scrutiny.
Modern AI systems are increasingly adopting the same philosophy.
The goal is not to create a model that never makes mistakes. The goal is to create a system in which mistakes are more likely to be detected before they reach the user.
This shift in perspective is important because it changes how we think about reliability. Early discussions often focused on building sufficiently intelligent models and expecting accuracy to emerge naturally. Increasingly, practitioners have discovered that reliability is as much a systems problem as it is a model problem.
The most dependable AI applications are often not the ones with the largest models. They are the ones surrounded by the strongest verification mechanisms.
Rather than asking a model to be perfectly truthful, modern AI systems increasingly require it to justify its claims with evidence.
Fluency Is Not Truth
When the Mata case first became public, many people treated it as a cautionary tale about artificial intelligence. A lawyer had trusted a chatbot, the chatbot had fabricated legal precedents, and the resulting embarrassment played out in a federal courtroom. The story was easy to summarize and even easier to mock.
Yet focusing solely on the mistake risks missing the more important lesson.
The real significance of the incident was not that an AI system generated false information. Humans have always generated false information. Experts misremember details. Journalists publish corrections. Scientists retract papers. Entire fields of knowledge have been built on assumptions later proven wrong.
What made the Mata case unusual was the manner in which the information was presented.
The fabricated cases did not look suspicious. They did not contain obvious errors or absurd claims. They resembled legitimate legal citations closely enough to survive multiple layers of human review. Their authority came not from evidence but from presentation. They sounded like the sort of thing that should have been true.
For centuries, humans have relied on similar signals when deciding what to trust. Confidence often suggests competence. Professional language suggests expertise. Detailed explanations suggest understanding. These shortcuts are imperfect, but they have generally worked well enough because the effort required to appear knowledgeable was often tied to actually acquiring knowledge.
Large language models break that relationship.
For the first time, we have systems capable of producing convincing explanations, professional writing, and confident answers at enormous scale without possessing any inherent understanding of whether those answers are correct. The output can sound identical to expertise even when it is built on incomplete evidence, faulty assumptions, or pure fabrication.
This does not mean AI is uniquely deceptive. Nor does it mean the technology is fundamentally unreliable. In many situations, modern language models are remarkably useful. They summarize documents, explain concepts, assist with programming, and accelerate research in ways that would have seemed extraordinary only a few years ago.
The challenge is learning to use these systems for what they are rather than what they appear to be.
A language model is not a database. It is not a search engine. It is not an expert witness. At its core, it is a probability machine trained to generate plausible continuations of text. Sometimes those continuations happen to be correct. Sometimes they are not. The distinction cannot be determined from confidence alone.
Perhaps that is why hallucinations continue to attract so much attention. They reveal a weakness not only in our models but also in ourselves. The Mata attorneys trusted the citations because they looked authentic. Most of us would like to believe we would have done better, yet the success of hallucinations depends precisely on their ability to appear credible.
In that sense, the problem extends beyond artificial intelligence. The same critical thinking skills that protect us from misinformation, misleading statistics, and unreliable sources remain necessary when interacting with AI systems. The technology has changed, but the underlying principle has not.
Truth still requires evidence.
And no amount of confidence can replace it.
Sources & Further Reading
The Case
Mata v. Avianca, Inc. (Court Docket)
https://www.courtlistener.com/docket/63107798/mata-v-avianca-inc/Mata v. Avianca, Inc. (Sanctions Opinion)
https://www.courtlistener.com/docket/67104031/mata-v-avianca-inc/
Hallucinations
Cognitive Mirage: A Review of Hallucinations in Large Language Models
https://arxiv.org/abs/2309.06794A Survey of Hallucination in Natural Language Generation
https://arxiv.org/abs/2202.03629A Survey of Hallucination in Large Foundation Models
https://arxiv.org/abs/2309.05922Sources of Hallucination by Large Language Models on Inference Tasks
https://aclanthology.org/2023.emnlp-main.245/Siren's Song in the AI Ocean: A Survey on Hallucination in Large Language Models
https://arxiv.org/abs/2309.01219
Calibration & Uncertainty
KalshiBench
https://arxiv.org/abs/2512.16030Scikit-Learn Probability Calibration
https://scikit-learn.org/stable/modules/calibration.html
Verification & Mitigation
Retrieval-Augmented Generation (RAG)
https://developers.llamaindex.ai/python/framework/understanding/rag/LangChain Reflection Agents
https://www.langchain.com/blog/reflection-agentsLangGraph Multi-Agent Architecture
https://towardsai.net/p/machine-learning/langgraph-multi-agent-architecture-building-a-self-critiquing-ai-debate-system
Comments (0)
No comments yet. Be the first to share your thoughts!